MozFest Accessibility with Hyperaudio
As you can tell from our new homepage there are a few directions in which we can take Hyperaudio.
Fundamentally Hyperaudio is about making audiovisual media accessible and we do that through metadata. In our case the metadata are Interactive Transcripts which we tightly couple with audio or video files.
Numerous forms of accessibility emerge from transcripts. Perhaps the most obvious is access to people with hearing impairments. Having a timed transcript skip along to a person’s voice (karaoke style) not only communicates the words being said but also a sense of pace and rhythm.
For those who prefer to keep their eyes firmly on the video, we can convert this metadata to captions and translate these captions into a number of different languages, giving us more levels of accessibility.
Additionally we can use Interactive Transcripts as a base from which to mix and remix media, providing a shallow learning curve for the creation of new pieces – another level of accessibility not just for consumers but also for creators.
In this blogpost I’ll write about the trials and tribulations of piloting Hyperaudio for Conferences with the Mozilla Festival which for the first time happened virtually this year. Hyperaudio has been part of MozFest on and off for nearly 10 years now (!) and so it seemed a good fit.
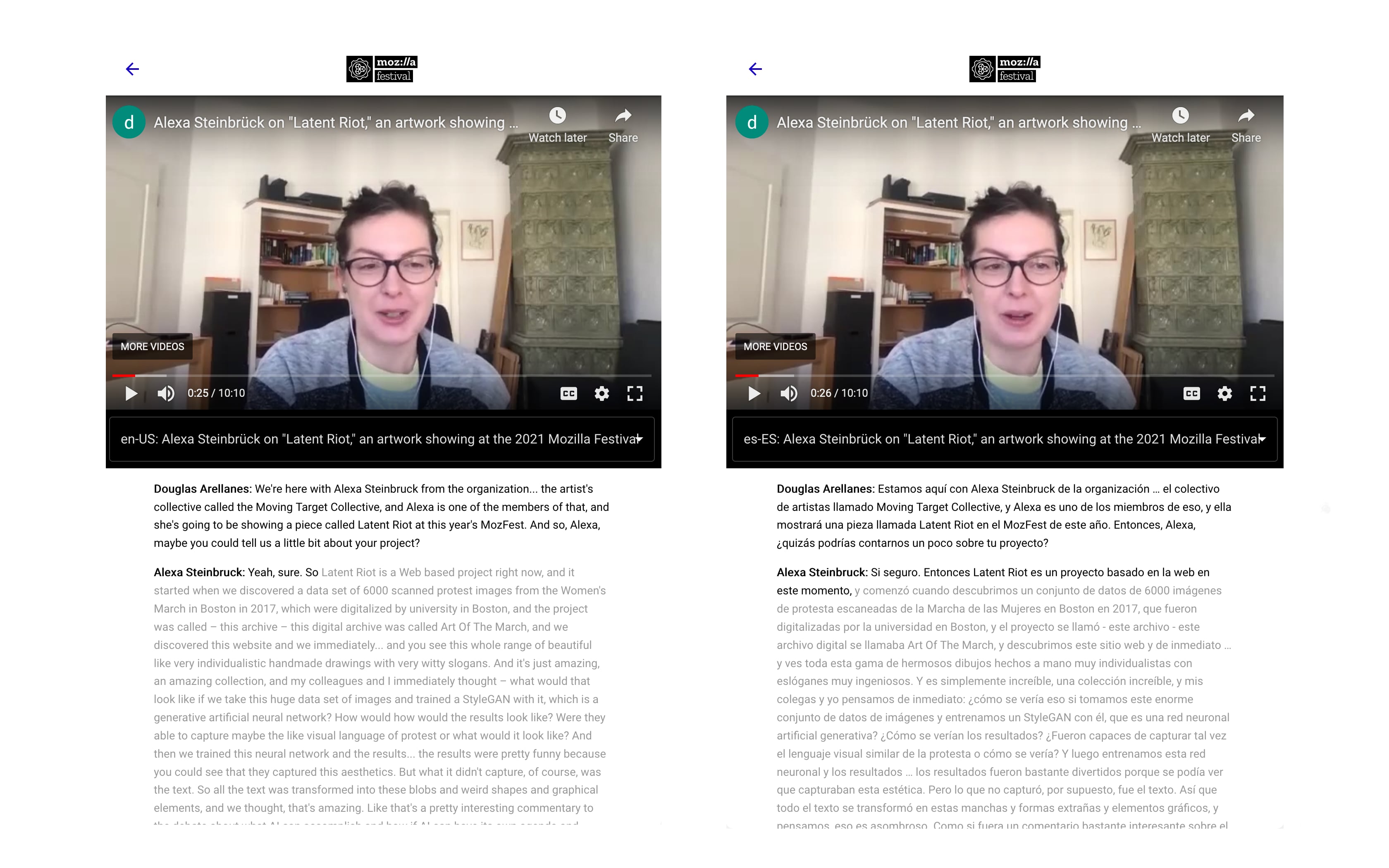
Why the conference use case?
More than ever conferences are taking place online and so it makes sense to take this often recorded content and make it as accessible as possible to conference goers and new potential audiences.
That’s not to say that conference material should be accessible to all, later I’ll talk about how this content can be monetised.
So let’s take a look at the advantages in using Hyperaudio with conferences:
- Timed transcripts make it easier to navigate and search content
- Timed transcripts can be automatically converted into captions
- Timed transcripts and captions can be automatically translated into other languages
- Timed transcripts can be used as a basis for intuitive editing and mixing
- Parts of timed transcripts can be indexed, referenced and shared
- Parts of timed transcripts can be annotated or commented upon
And for balance let’s take a look at the investment that needs to be made for all of the above to be viable.
Costs
First let’s look at costs for machine transcription – this averages out at around $1.50 an hour and then there’s machine translation which comes in around $15 per million characters. These figures are based on Amazon’s offerings but similar services are comparable.
Then there’s human costs – machine transcription is rarely 100% accurate and so it will often needs to be corrected for best results.
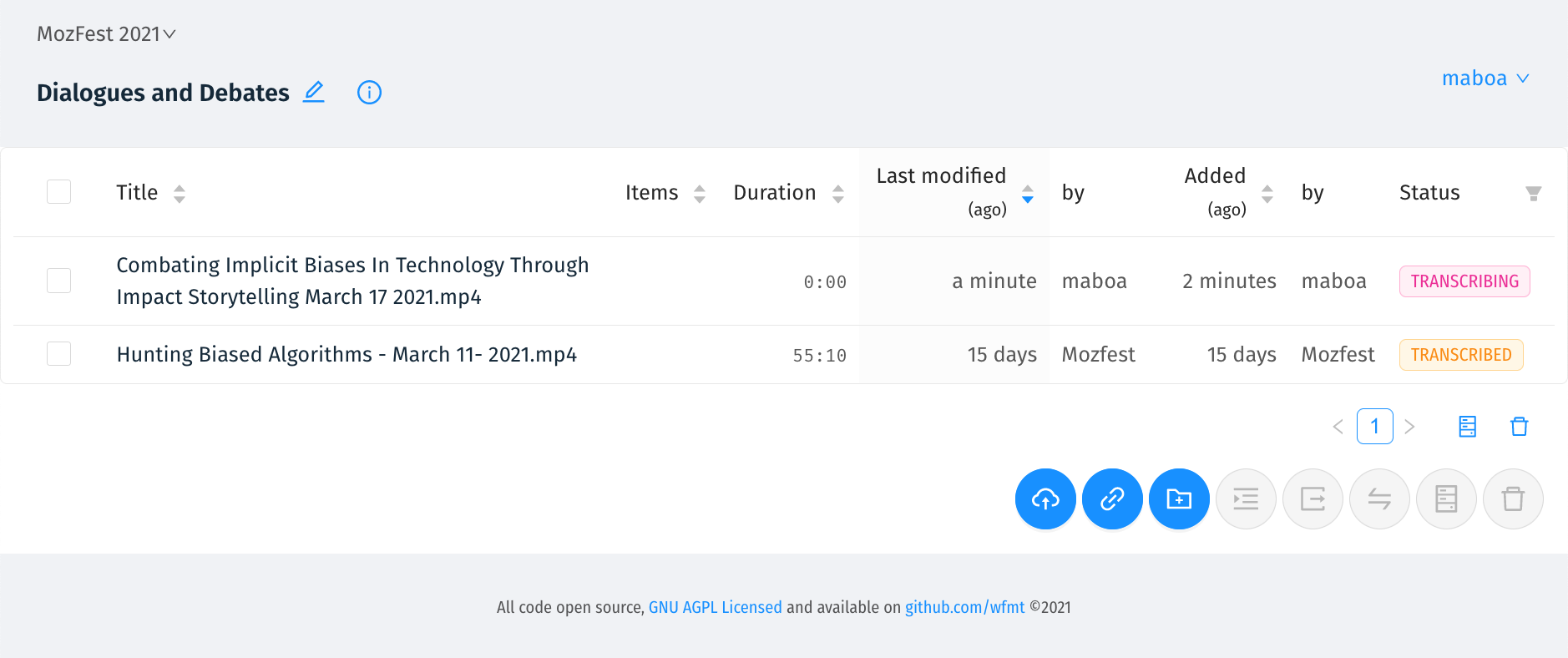
We’ve measured that correcting the average transcript will take 3 - 4 times the duration of the original media. So an hour long session could take 4 hours to correct. A good timed text editor can help significantly and it’s something the Hyperaudio team have built before, we even started a business around the concept.
Fortunately we’ve learned and are still learning a lot about editors and the editing process, due in no small part to work we’ve done with the BBC News Labs. One feature we’re really excited about is something called the Overtyper that should speed up editing.
In the true spirit of prototyping an idea, in the interim we're trying to as much as we can with elements we've already built. As an editor we're using the Open Editor – a "work in progress" open source transcript editor which the Studs Terkel Radio Archive has sponsored us to create.
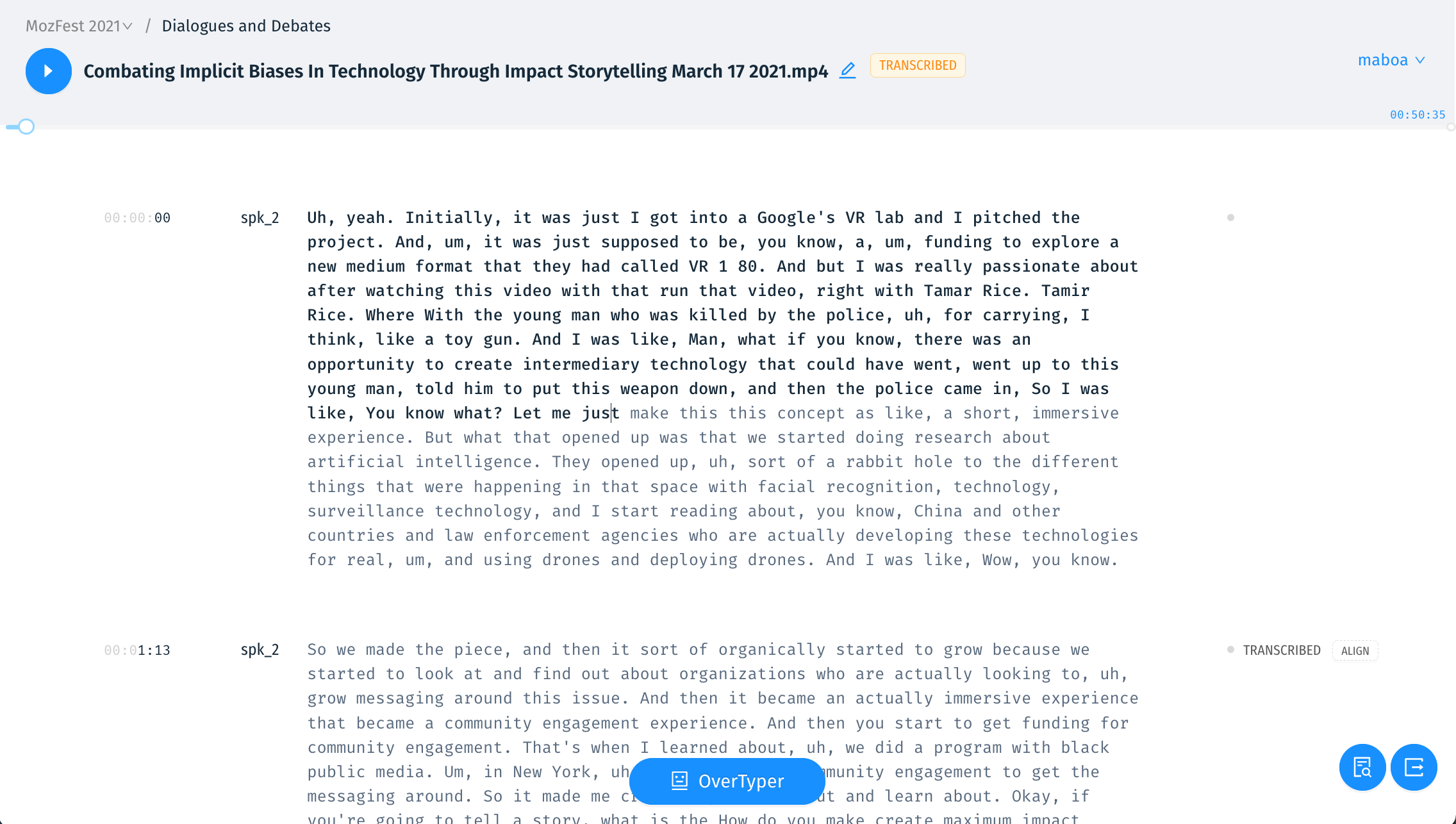
The last thing I’ll say about editing transcripts is that for remixing purposes it’s vitally important that the corrected transcripts are accurately time-aligned – we can do this in English using the open source Gentle but we’re looking to train or write something that does this in a number of languages.
Captions
We’ve generated captions from timed transcripts before, so we have experience in this area but this time we wanted to ensure that the algorithm worked for all languages – we have something that seems to work ok for English and other European languages, we feel like more work is required for it to work with languages like Mandarin and Japanese. In general though our approach is to make a best guess and let administrators adjust.
Incidentally we feel that a timed-text-to-captions module is a prime candidate for open sourcing with a liberal licence.
Translation
A big selling point of Hyperaudio for Conferences is the promise of near-automatic translation. "Near-automatic", as the first pass is automatic, with the option for people to tweak.
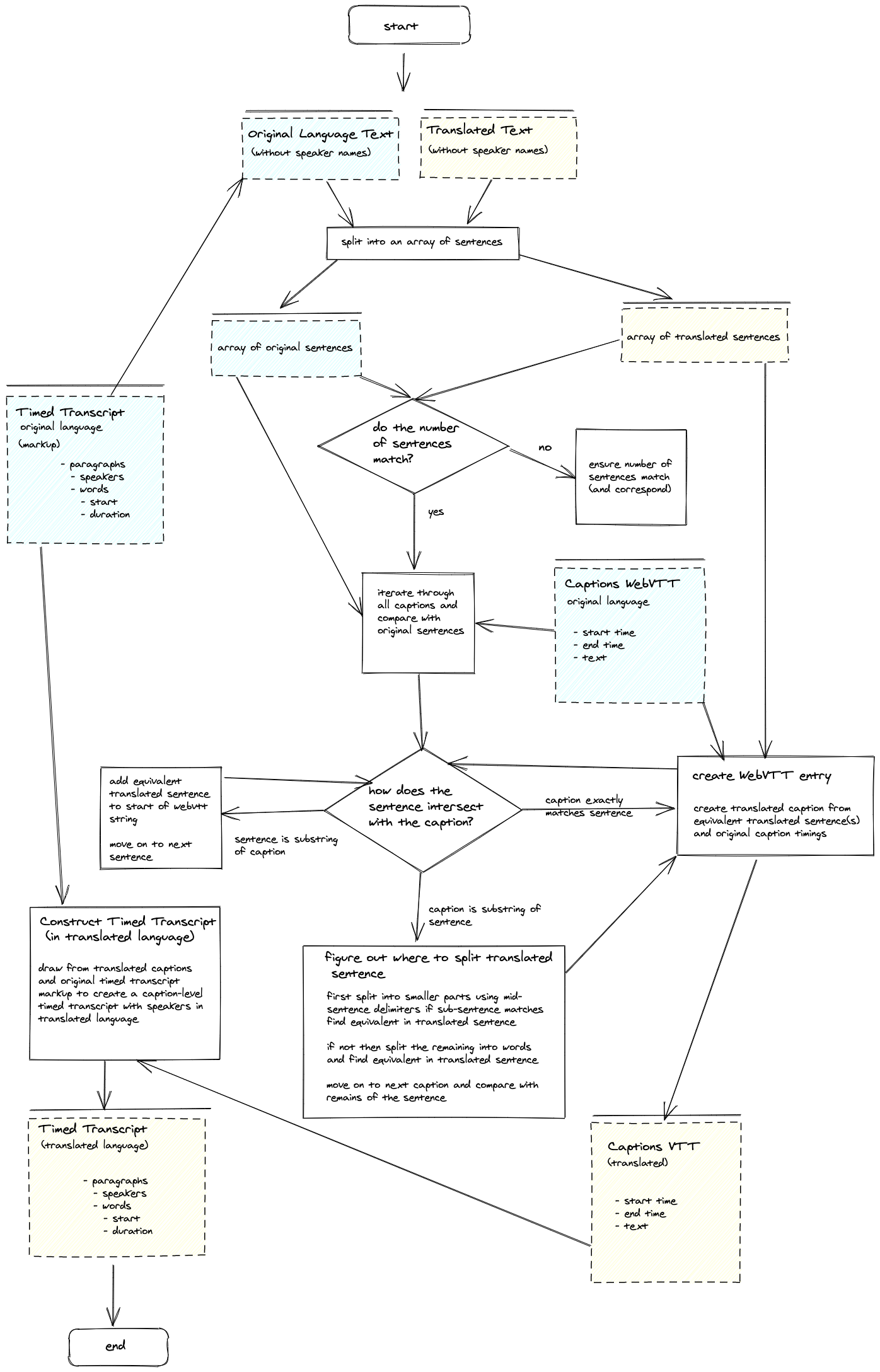
From the diagram you can see that translating captions and timed-transcripts involves a little bit of complexity. The algorithm we’re currently using relies on the sentences of the original transcript and the translated transcript matching.
The current algorithm runs client side, but if we do this server side we can use Bleualign and/or hunalign to match sentences and which will reduce the need for manual matching.
Unexpected Issues and Advantages
Our biggest issue to date has been finding facilitators willing to commit the time needed to correct transcripts. That’s partly because MozFest is a volunteer run festival and facilitators already had a lot on their plate.
We anticipate that for most virtual conferences, where organizers want to benefit from the Hyperaudio platform, resources will be allocated to transcript correction.
The takeaway from this that it’s our job is to make editing and correction as easy, satisfying and as fun as possible - combined with increasingly accurate transcription and the opportunity of creating custom dictionaries, this should make correction more palatable.
There were also a few advantages of transcribing recorded conference calls. One thing we noticed from the material is that some videos start a while before the participants arrive, so there is a lot of dead time at the start. Of course it’s fairly easy to skip through that with the YouTube player, but it’s not as accessible as clicking on the first word of an interactive transcript.
Technical or organizational issues can occur during a session which is all part and parcel of the live experience, but not essential viewing after the event. What Hyperaudio does by transcribing is layout all the content in front of you with an intuitive way of navigating and skipping content.
As we roll out the remixer we imagine tighter cuts of content being made available, where dead time and technical issues are left out from the mix.
We also learned from MozFest that some people may be uncomfortable with content in which they feature being indexed and available to all. MozFest handles this by creating unlisted YouTube recordings (to be taken down in 90 days) and linking these from the conference schedule, which is only available to attendees. We're looking into mirroring this type of access and can potentially go further by allowing participants to be removed from videos and/or their content anonymised.
Finally one unexpected advantage I personally discovered was that by reading the transcript as it lit up karaoke style I could consume content at 2x playback speed and still understand it, then again maybe it’s faster just to read the transcript!
A Note on Revenue
We’re part of the Grant For The Web community looking to use the Web Monetization API as a way of generating revenue. It’s fairly easy to build in and so we have that activated from the start – and although we haven’t added any content from the conference yet, I’m pleased to say that revenue is in double digits! :)
At the end of the day we'll let the conference organiser decide how they want to gather any revenue but we want include Web Monetization as an option. We'll allow them to make some content accessible exclusively to those with a Web Monetization compatible wallet. But we also want to give the organiser the option to distribute some of that revenue to people creating mixes and sharing, thereby encouraging new content to emerge. I wrote more about this here.
Thanks
As an unfunded pilot we've been working on this in our "spare" time, this means putting things together using existing bits and pieces and relying on the goodwill of the team – Laurian Gridinoc, Piotr Fedorczyk and Joanna Bogusz. I'd also like to thank Nic Wistreich, Allison Schein, Annabel Church, Lou Huang, Douglas Arellanes, Gracielle Higno, Lujain Ibrahim, Philo van Kemenade, Chinouk Filique, Zannah Marsh, Sarah Allen, Steph Wright, Marc Walsh and Chad Sansing for their encouragment, help and support.
Cover image – " Karaoke at Shibuya" by DocChewbacca is licensed under CC BY-SA 2.0![]()
![]()
![]()