The Way We Speak
It’s not entirely obvious until you see speech written down, quite how people speak in uniquely different ways.
Speech, unlike written language, is often direct, live and improvised. Sentences may or may not be grammatically correct, or even make any real sense when taken out of context.
People stutter, repeat, misspeak and use an inordinate amount of filler words to get their point across – and this of course is the main thing. Getting points across.
Speech is a very imprecise way of communicating. And we’re constantly adapting to situations which are often in a state of flux – adding uncertainty, caution, surprise, incredulity and a whole range of other human aspects to our utterances, through cadence, intonation and of course word choice.
Speech-to-text technology allows us to see spoken words “written down”. And seeing that speech written down allows us to see it for what it really is.
A beautiful word soup!
So when I started editing the output of speech-to-text algorithms for our latest Hyperaudio based project – Hyperaudio for Conferences, I was faced with a number of dilemmas – which words to keep, which to throw away, how to represent the fact that sentences have started, stopped, changed direction or been abandoned completely. The twists and turns of the human mind at work.
The twist for us is that with Hyperaudio we represent speech as timed text. That is to say that for every word transcribed, we maintain a start time and a duration. We represent both words and timings as an Interactive Transcript – so we can see words light up as they are spoken. Reminiscent of karaoke but with the added feature of being able to click on those words to hear them spoken from that point.
Dilemmas
A core mission of the Hyperaudio Project is to make audio and video more accessible. One of the ways we do this is to allow people a method to translate transcripts. To make this as easy as possible we provide a side-by-side view of the original and automatically translated language. The idea being that somebody can come in and verify and correct the translation – since automatic translation is never perfect and can, at times, be misrepresentative.
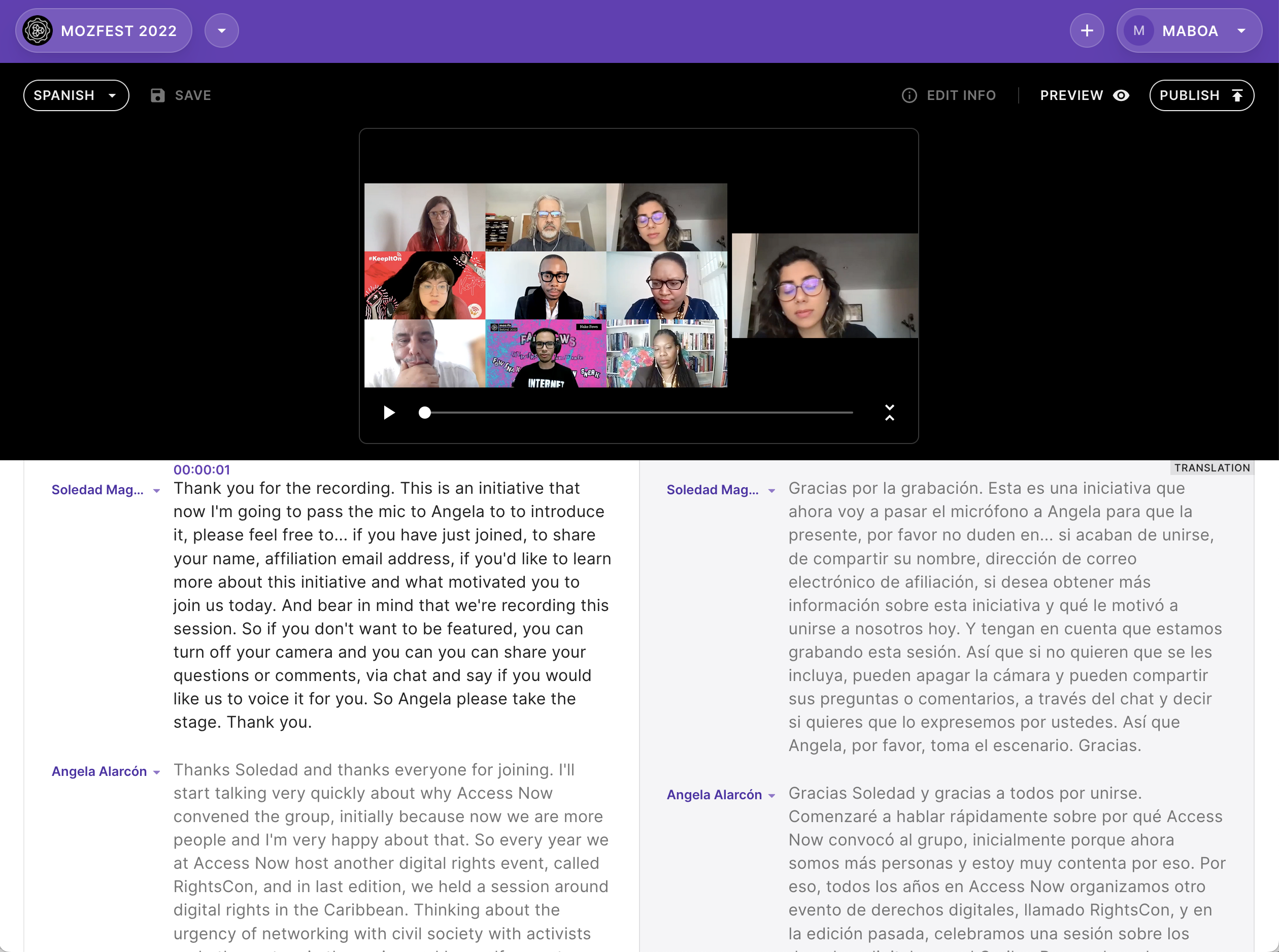
By ensuring that the original transcript is in “good shape”, we minimise the chances of mistranslation and how much work people need to do to produce acceptable translations.
One dilemma stems from the fact that the translation algorithm works better when filler words, also known as disfluencies, are removed. This also has the side effect of making transcripts more readable. However the price we pay is that our transcripts are less expressive and less representative of the things that people actually say.
If you watch professionally captioned videos, say popular dramas on your favourite streaming service, you’ll often notice that some level of disfluencies are included in the captions. I imagine this is primarily to preserve the expressiveness of speech as much as reasonably possible.
One big dilemma then, is how much "filler" to remove. A second is how to represent disfluency as text.
It’s like…
Um, uh, er, like, you know, kinda, so – are all types of filler words we encounter in spoken English.
And as far as I’m aware, each language has their equivalents. In Italian you might find speech liberally smattered with “cioè” which loosely translates to “i.e”, “that is” or “namely”. I’m reminded of being on a bus in Edinburgh and wondering who this Ken character was that everybody was talking about. It turns out “ken” means “you know” in Scottish dialect.
Ideally I think we’d leave these words in, by and large. Everyone has their own particular way of speaking, it’s part of people’s personality and it feels a shame not to expose that.
But words like “like” can be interpreted as non-filler words by translation algorithms.
For example Google will translate
“I'd like to make, like a great job of like this translation.”
into
“Mi piacerebbe fare, come un ottimo lavoro come questa traduzione.” in Italian.
Which is not the best representation. Interestingly translating English into Spanish we get …
“Me gustaría hacer un gran trabajo de esta traducción.”
Where the 2nd and 3rd “like” are ignored.
Back to Italian, maybe punctuation can help.
“I'd like to make, like, a great job of like, this translation.” translates to
“Mi piacerebbe fare, tipo, un ottimo lavoro con questa traduzione.”
Note that the 2nd “like” becomes “tipo” which is a similar filler word to “like” in Italian and the 3rd is dropped!
So punctuation may help. Unfortunately translation algorithms can be both imprecise and inconsistent.
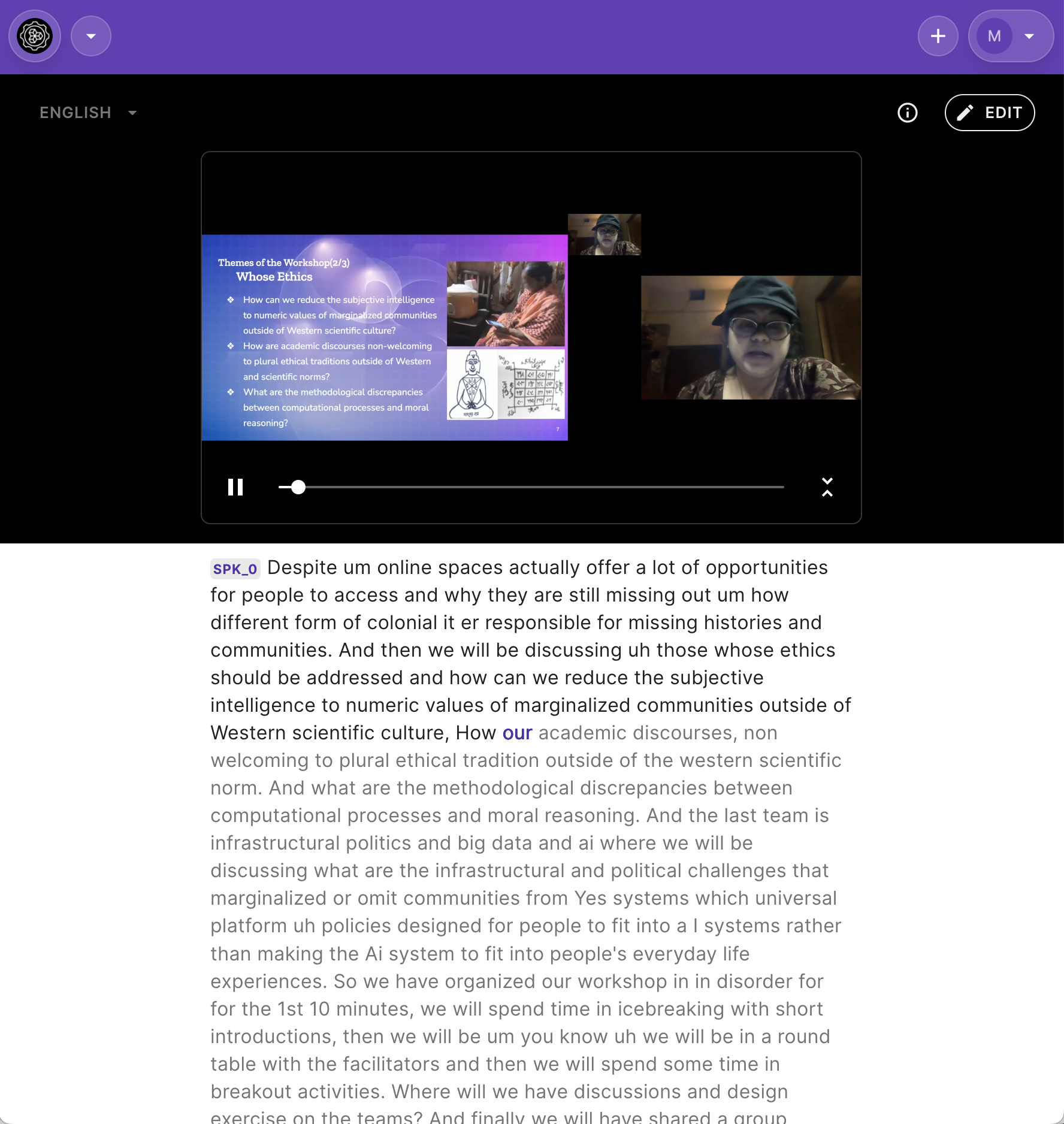
Biases
Another important issue is bias, when you “correct” a transcript you are effectively making a series of editorial decisions. Which mean biases can creep in – subconscious biases you may have about the speaker’s class, status, nationality, ethnicity or gender could all affect the edits that you make to the text representation of their speech, especially when these factors affect those speech patterns.
Of course algorithms are also biased. Soledad Magnone one of the facilitators at MozFest and the editor of Activating Caribbean Digital Rights: Embracing Change in Digital Epistemology wrote to me about gender inclusive language.
Soledad wrote:
When translating resources I've been using different alternatives. For example:
1. "Welcome" > "Bienvenida(o)" - using the feminine first.
2. Alternatively you can use both "Bienvenida and bienvenido".
3. Bienvenidx > alternative including all genders, not strictly binary. This is problematic as not possible for accessibility systems to read.
4. Bienvenide > alternative to the above, however, also not recognised by official language academies nor its use is extended.
For Hyperaudio I've made adjustments mostly using the second option.
Wanted to share this information as it might be of interest for Hyperaudio developments for Spanish and other languages in relation to gender inclusion.
Ideally
Since we started working with transcripts, I have corrected many hours of transcripted audio. It’s only more recently that I’ve started considering the fact that the transcript should be optimised for automatic translation.
But humans are also the target, and as I mentioned, it might be nice to expose human elements to other humans. And in doing so make sure our translations are gender inclusive.
So what’s the solution?
I don’t have a definite answer, but I think ideally you would flag which parts are filler words or disfluencies, so that you effectively have two views of the same transcript. And then maybe you’d submit the version without fillers to the translation algorithm and display the more “natural” version to the viewer (with perhaps the option to turn disfluencies off and on). Ideally the speech-to-text algorithm would be able to flag these automatically.
Since we have the timings we could also skip those filler words in the audio, but that probably has more application with audio destined for a podcast.
It would also be possible to keep look-up-tables of gender inclusive words, although it's a daunting task to do this in every language – it sounds like an ideal candidate for a community resource.
Or perhaps, in time, translation algorithms will become better at translating natural language and provide options (even defaults?) for gender inclusivity.
Timings
Finally, a word or two about timings. Timings are important for us as we use the timings of words to facilitate navigation – if you click on a word in a transcript, you go directly to the time point that the word was spoken. Playing back the media results in words highlighted in time.
Accurate word timings also allow us to select and share snippets of media and facilitate the feature that makes Hyperaudio unique – the remixing of media using text as a base.
All this means that if we remove words, we remove a reference to those words, so we need to bear all this in mind.
Conclusion
Although satisfying, editing timed transcripts can be hard work and consists of a number of editorial decisions that should be made with both humans and computers in mind.
Removing too many filler words to improve the readability of the transcript and the quality of translation currently comes with trade-offs and may expose biases.
On reflection, I feel that I may have been too heavy handed in my editing in the past and so I’m probably going to go back and restore some of those deleted words.
Ultimately though, we need to figure out ways of making our transcripts work for both humans and computers, without putting too much of the burden on the editor of the original or translation.
Cover image – Cuba - Havana Public Artwork - Mar 2014 - Empty Headed Conversation by Gareth1953 All Right Now is licensed under CC BY 2.0![]()
![]()
This post and all other images are licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. 