Hyperaudio for Conferences and Grant for the Web
A few weeks ago we received the exciting news that our application for funding from the Grant for the Web (GftW) programme had been accepted for a flagship level grant. This was our second application for funding, our first was considered a little too ambitious. Luckily GftW have a progressive policy of giving applicants a second chance in response to feedback from their team.
So we switched tack slightly and decided to concentrate on one particular use case – conferences.
So what is it we decided to make exactly? Some excerpts from the revised GftW application might help explain:
Hyperaudio for Conferences is a web-based platform to which conferences can add recorded content maximising accessibility, engagement and revenue.
Speech-to-text engines provide timings to accompany the text transcribed. We use this timed-text to maximise accessibility by creating an Interactive Transcript linked to existing audiovisual content exposing content to search engines. Words “light up” as they are spoken – reinforcing comprehension and can be used to navigate.
We automatically generate captions and translate those captions into a number of languages – opening up conference material to people who are disabled, have learning difficulties or who may not understand the original language.
Using timed text as “anchor” points, associated media can be mixed or shared by selecting pieces of text. Additionally, slides can be displayed at specified time-points.
Sharing excerpts of conference material becomes a matter of highlighting text and selecting the destination. Since we have the text, timings and the video, we can create captioned video clips tailored for social media. We can incentivise this sharing through web monetized payments.
We’ll also use Web Monetization to ensure that viewers only pay for what they consume and that funds can be transparently divided between content creators, remixers, sharers and our service.
The Conference Use Case
We were (and still are) looking to apply Hyperaudio technology to a number of use cases – some of which are outlined on the current hyper.audio front page. From the signup form to our newsletter we've gathered the following data:
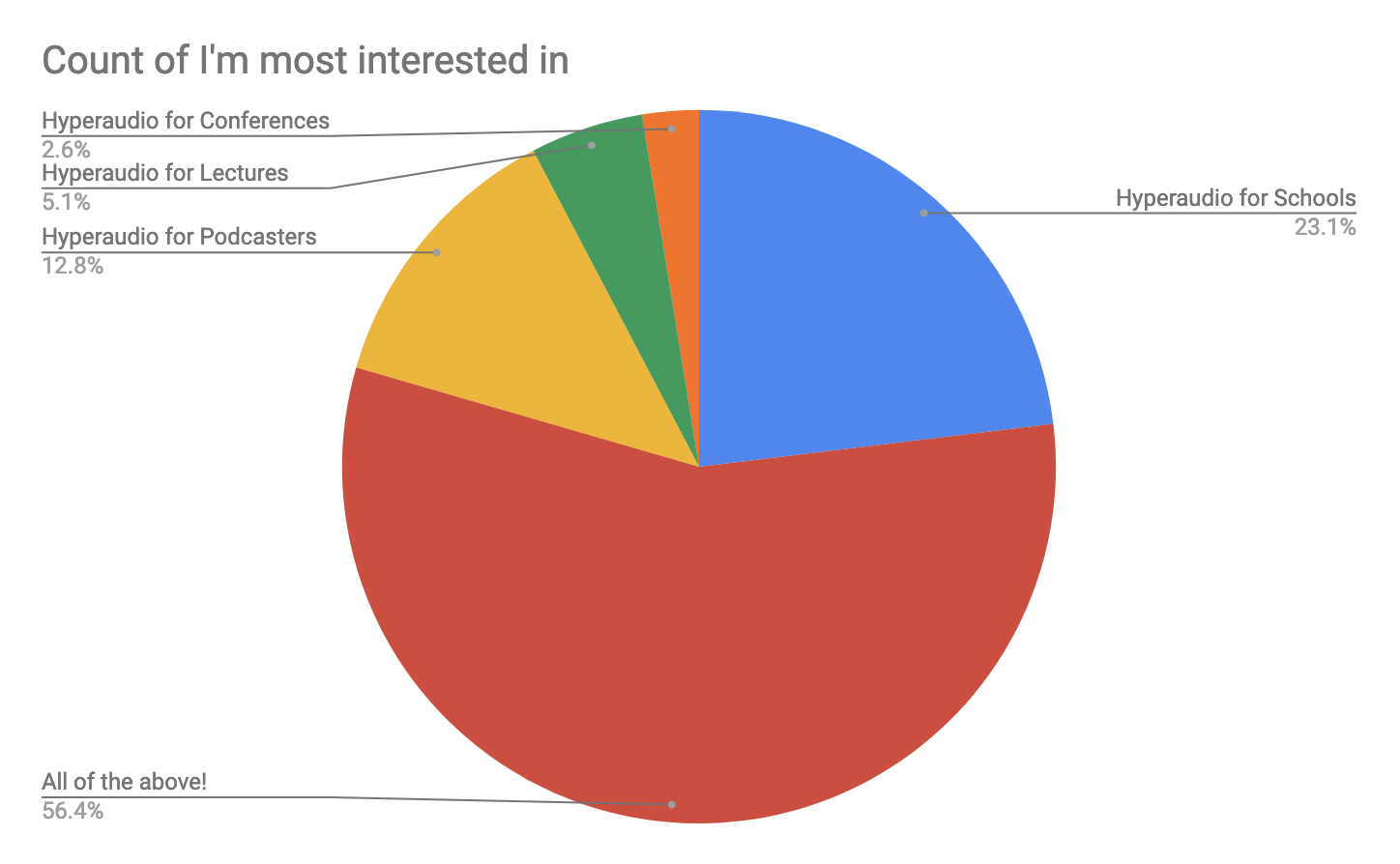
As you can see the conference application is not the most popular use case, but that's ok – initially we want aim for a market with a smaller number of higher paying users and our research leads us to believe that we're on the right lines.
From Speechmatics' Industry Report – Trends and Predictions for Voice Technology in 2021:
44% of respondents think that voice technology will have the largest commercial impact on web conferencing transcription in 2021.
Web conferencing has become a key part of our lives over the last year and this isn’t expected to change. The pandemic has meant individuals have had to depend on these technologies not only in work environments but to stay connected to friends and family. Web conferencing tools have become well known and easy to use. With the most basic functionality often free, they are a staple communication channel.
Voice technology can further enhance web conferencing through improving accessibility with real-time captioning or deriving insights from calls by providing post-call transcripts. Web conferencing organizations have benefited greatly from the pandemic, placing huge demand on their services. Revenues have soared and with that has come increased budget to drive innovation. This popularity has also increased competition in the market with startups trying their hand at taking a chunk of market share.
And regarding subtitling and captioning:
27% of respondents believe that voice technology will have the largest commercial impact on subtitling & closed-captioning.
Additionally, using voice technology to generate accurate subtitles and closed captions increases the accessibility of video assets. Whether deaf or hard of hearing, or situationally disadvantaged, captions drive video views and engagement.
Captioning is now demanded by legislation and will continue to be a challenge for organizations to deliver as content creation increases as expected. In 2021, organizations will need to improve their captioning capabilities and will adopt next generation tools like speech recognition technology. Additional features such as punctuation, speaker diarization and a diverse language offering will be key to help media teams keep up with the legislation brought about by the Federal Communications Commission (FCC).
The Mozilla Festival Pilot
Market research aside we were eager to run a pilot to gauge opinion, test a few assumptions and encounter any unforeseen issues, early.
We had already worked with another GftW grantee to transcribe some conference content and provide an Interactive Transcript player for CiviCRM conference – CiviLive, which was well received and since I was involved with the organisation of this year's Mozilla Festival it made sense to pilot our Hyperaudio for Conferences platform with them.
So with Mozilla's blessing we created a subdomain for hyper.audio and set to work. Since we had a tight deadline and limited resources, we kept things pretty simple but this allowed us to try out some key features, some of which we'd never tried before. This is what we learned...
Correcting Speech to Text
The problem is that as good as STT has become, resultant transcripts are rarely 100% accurate. Often algorithms struggle with overlapping speech, accents, specialist terms and names. The challenge then is to provide an efficient transcript editor, that makes the process of correction as painless as possible, while still preserving those precious word timings useful for remixing and creating captions.
Thankfully we've created transcript editors before. The original Hyperaudio had a tool we dubbed The Cleaner. Soon after we went on to found Trint and three members of the original Hyperaudio Team went on to create Trint's transcript editor, which remains broadly the same to this day. Since then we've created various transcript and caption editors for the Studs Terkel Radio Archive and the BBC.
The key issue is that it takes significant time to correct transcripts – and importantly for sessions with more than one speaking participant, assign speaker names to passages of text. From our measurements, sometimes it takes up to four times the length of the media duration to correct. The process requires the person editing to make various judgment calls, as people's speech patterns vary. Editors need to decide how to represent those disfluencies in speech – the unfinished sentences, changes in direction and repeated words.
So a big focus for us will be to make the editing process as efficient as possible. Part of the solution is to take advantage of STT services' support for custom vocabularies. So our approach could be to pre-populate a dictionary with speaker names and session titles and invite the organiser or editor to edit the dictionary. We'd also provide a conference-wide option, so for example if you're running a conference on cicadas, you can include a cicada related dictionary for all sessions.
OK. Time for a little story about open source and collaboration. Back in 2017 a group of us gathered at New York University (NYU) for the TextAV meetup organised by Pietro Passarelli and Ben Moskowitz. It was at this meetup that I posited the idea of the Overtyper – a way of correcting transcripts inspired by the way we tend to correct people (especially children) when they misspeak. The way it works is that you listen and view the transcript and retype or respeak any part that the STT algorithm gets wrong, since we are able to tell where we are in the transcript the Overtyper then makes an educated guess as to where the new text should go. In 2018 our TextAV meetup took place in London and I was delighted to discover that Chris Baume had written a version of the Overtyper and published on GitHub under the MIT license. Since then we've run some trials and it looks like we can significantly reduce the editing time by using it.
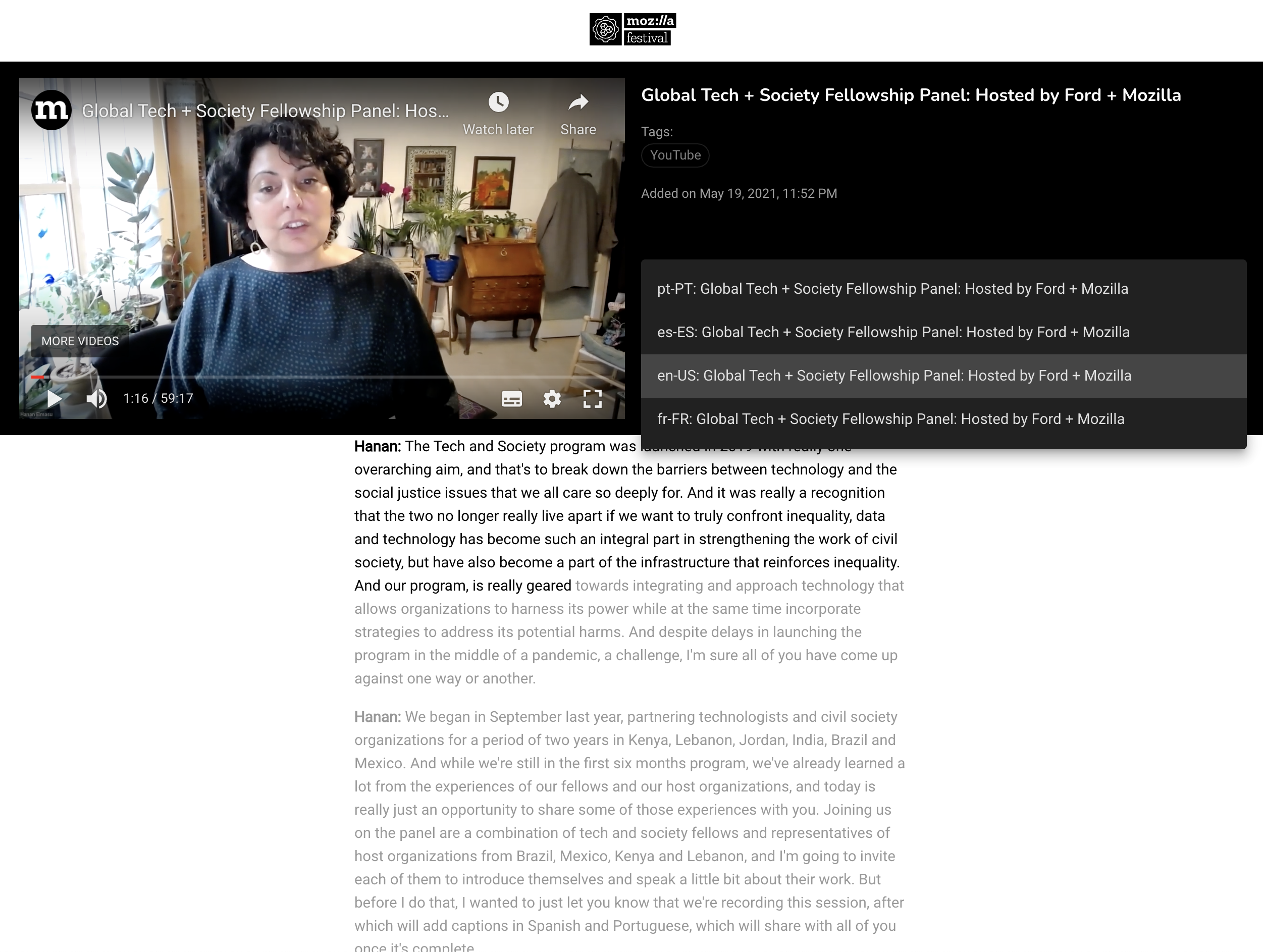
Image –
Screen from MozFest Pilot CC BY-SA 2.0![]()
![]()
![]()
Translation
The translation aspect of this pilot was semi automated and so there was some manual work involved, which took longer than anticipated. Things that seemed trivial (like preserving speaker names between translations) ended up being more fiddly than expected. But overall we're happy with the results.
We tried Amazon and Google Translation APIs and there seemed no real advantage of submitting blocks of text (with supposedly more context) over sentences, so we opted to submit batches of sentences, which is slightly slower but has the advantage of guaranteeing the sentence to sentence mapping. We'll likely optimise the performance in the new version.
A useful insight from the translation process came when I spoke to Kim Patch – a user interface expert and fellow fan of Interactive Transcripts. I mentioned that since we couldn't maintain word timings between translations, our translations had caption level timings. Kim suggested we change this to sentence-level as that's how people read, so having sentences light up as they were spoken made more sense.
Feedback
We received some really useful feedback from the Mozilla Foundation regarding the potential for misrepresentation, privacy and anonymity which we are taking on board. In general we were really happy to see the positive reaction to our endeavours.
We are carefully evaluating the potential for abuse and other ethical aspects from the very start, so that we can build the appropriate mechanisms to minimise effects of any harmful behaviour that might occur, which is why the considered feedback from an organisation like Mozilla was so welcome.
We'll comment more on the ethical aspects in a separate blog post.
More info on the MozFest Pilot in this blogpost : MozFest Accessibility with Hyperaudio
Our Team
I'm extremely fortunate to be embarking on this project with an amazing group of people – a quick shout out then to Joanna Bogusz, Annabel Church, Piotr Fedorczyk, Laurian Gridinoc and Dan Schultz. We look forward to collaborating with other GftW cohorts to bring all our visions to life!
Title Image –
"Mozilla Festival" by Laurian Gridinoc is licensed under CC BY-SA 2.0![]()
![]()