Keeping Archives Alive: Resilience and Discovery on ATProto
The Black Reproductive Justice Archive (BRJA) gathers the voices of mothers, organizers, healthcare providers and scholars – first-hand testimonies about reproductive justice, in the words of the people who have lived it and are seeking to provide support for others.
 An interview from The Black Reproductive Justice Archive – published using the Hyperaudio Lite Wordpress Plugin
An interview from The Black Reproductive Justice Archive – published using the Hyperaudio Lite Wordpress Plugin
I worked on the BRJA while I was at TheirStory. Their funding was tight, so we published the interviews on the simplest, cheapest website we could manage. That was before the US elections.
After the US elections, as the political climate changed, while funding for projects like this was being stymied and information on various official sites was being whitewashed, I was making some modifications to the BRJA site and realised that we were now dealing with an archive of politically sensitive material, exactly the sort of content that could be a target of a political takedown. I wondered what it would take to make stories like these difficult to erase.
I'm currently working as an independent consultant. Since I started work on The Hyperaudio Project 15 years ago I've been a CTO of startups that have relied on Hyperaudio-like interactive transcripts. The first was Trint, a UK-based company I cofounded, which addressed a need for journalists to transcribe and correct interviews – I was in the journalism space at the time, working on projects such as Palestine Remix for Al Jazeera and The Studs Terkel Radio Archive. This segued neatly into my next role as CTO of TheirStory, an oral history platform which also puts Hyperaudio tech front, left and centre. I want to keep working in this space, with a focus on open source, decentralised systems and the judicious application of AI.
I've been active with the Mozilla Foundation over the years and have been lucky enough to attend and participate in many Mozilla Festivals, from running workshops to "wrangling" spaces. One of the spaces I wrangled for a couple of years was the Decentralisation Space and if you read back through this blog, you'll see a number of posts related to that time.
- Decentralisation - MozFest 2018 - a Facilitator's Perspective
- Decentralisation - MozFest 2018
- Decentralisation at the Mozilla Festival
At the time the decentralised AT Protocol (sometimes known as ATProto for short) was but a glimmer in Jack Dorsey's eye, but there was plenty of discussion about IPFS and its use as a way of getting around government blocking of websites, for example the Catalan government turning to IPFS to keep referendum information reachable as Spain blocked the official site. Even Tim Berners-Lee dropped by to set up a stand and pitch Solid, his take on letting people own and carry their own data. It was notable also that Renata Avila ran a session "Decentralization and Dignity against Digital Colonialism" where decentralised solutions were discussed as a way of preserving indigenous people's stories, something that we touched on at TheirStory but never quite managed to fully realise – although we collaborated with a Canadian organisation, Know History, who do great work in that area.
Due to my interest in decentralisation, ATProto had been on my radar for a while. Back in January I responded to a Bluesky post mentioning the publishing of transcripts for a 2025 Atmosphere conference asking whether they would like help making them interactive, I was asked to start a thread on Discourse and it sparked a low-tempo discussion but by the time I'd finished at TheirStory and properly got going, a second conference had taken place in 2026, and it's that content I'm working with now.
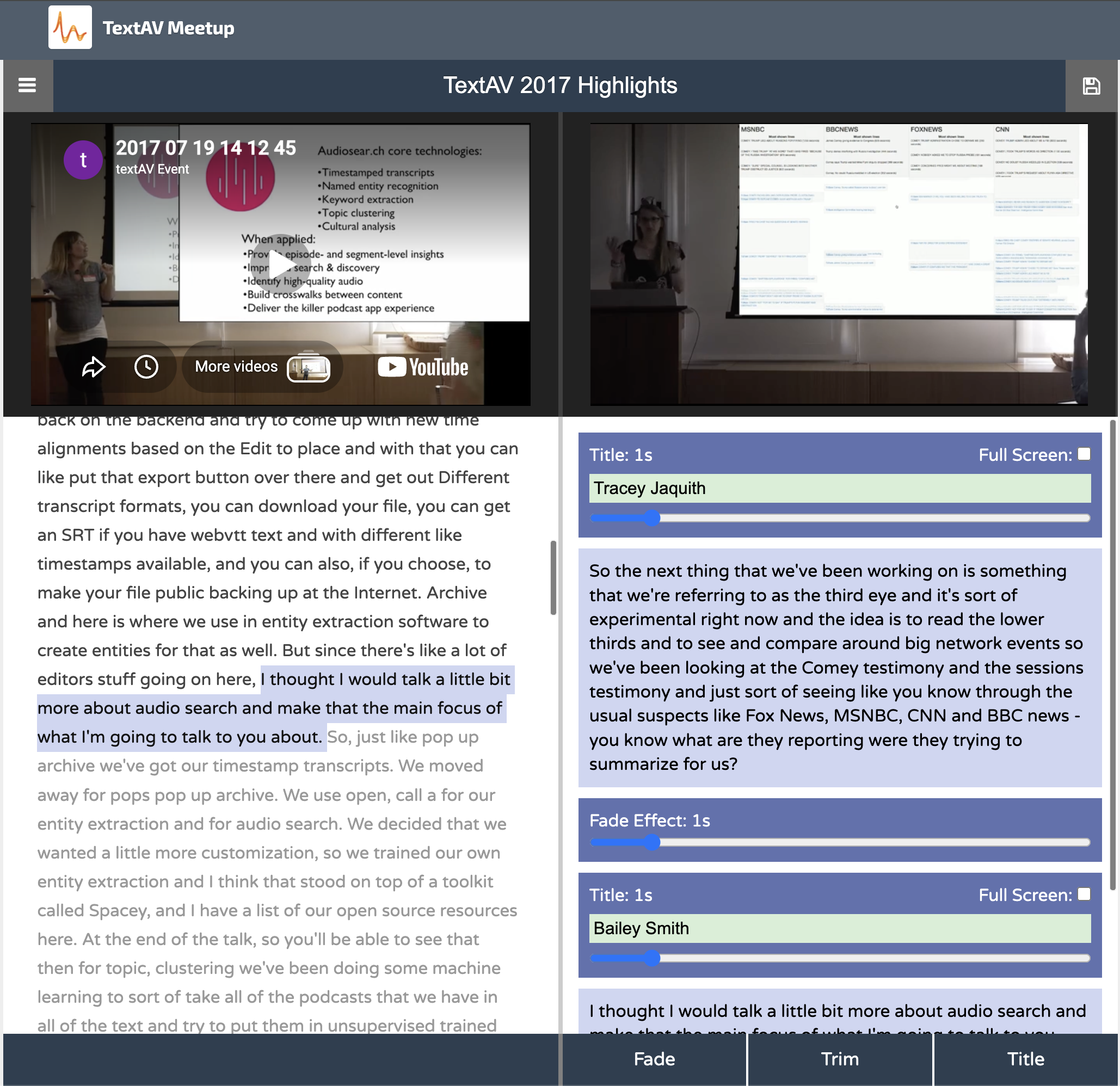
I have to say, it was a fairly steep learning curve! But the ATProto community took the time to explain the architecture to me (I had never used Astro or ATProto) and I managed to put a Proof of Concept together. That's when blaine.bsky.social entered the conversation. I know Blaine from the days when we used to have Text AV meet-ups, so I knew he had an interest in transcripts. Blaine also has a real history in the area of decentralisation – he was the first employee at Twitter and has been thinking about decentralisation for a long time.
What I didn't know was that he'd already built ionosphere – an archive that transcribes the talks through a Whisper-based pipeline and, crucially, defines a schema and ATProto lexicons (such as tv.ionosphere.transcript) for storing them on-protocol. This was gold – Blaine had already done the difficult part!
So with some LLM help I figured out an algorithm to convert Blaine's format to the format I was using and it seemed to work. Storing the transcripts on ATProto had already been hinted at and I think this was the long-term objective, but suddenly everything clicked.
Authenticity is a real concern with archival content. At root it's a single question – is this content exactly what its producer says it is? That has two sides to it. One is whether the content really comes from the source it claims to. The other is whether it's been altered since.
There are some centralised services that can help, one example is the Wayback Machine, but while the Internet Archive does indispensable work, relying on it as the sole backstop relocates the single point of failure. We know that it has already been challenged by several lawsuits that have threatened its existence.
One technology that has stood the test of time is IPFS, the general idea behind it was that data could be mirrored and verifiable. Remember the Catalan referendum websites?
I'm really interested in content addressing as a resilience layer. Content addressing is where data is identified by its content rather than by where it's stored – it's the idea behind IPFS, among other systems. It also helps with authenticity, which really comes down to two things – integrity (is the data unaltered, exactly as published?) and provenance (can we establish who published it?).
Content addressing lets us verify that content matches its hash, so we know it hasn't changed. But that only helps if we know the right hash to check against – and where do we publish that authoritative hash? A website can be hacked, altered, or taken down. A DNS record is only as trustworthy as whoever controls the domain. This is where the two sides come together – we could perhaps publish the hash as a signed ATProto record, bound to the publisher's identity and replicated across relays. The signed record establishes who vouches for the hash. The hash establishes that the content is intact. (Note: content addressing makes the content verifiable, but not automatically distributed – keeping copies alive is a deliberate act.)
To summarise – Authenticity = Integrity + Provenance + Durability:
Integrity = has it been altered? → answered by content-addressing (tamper-evidence).
Provenance = where did it come from / who's behind it? → answered by the signed ATProto record bound to a DID.
Durability = will it still be there? → not automatic, requires deliberate mirroring.
At this point I think it's worth stepping back and being clear-eyed about who this does and doesn't help. At least in the short-term a lot of archives may not be able to justify the added complexity and workflow involved in putting their data on a decentralised platform. But for those who harbour concerns about sites being taken down, or someone muddying the waters around what's genuine, this could definitely be a route to consider. If you add to that the potential exposure of archives for educational purposes, I think the case is compelling and something that definitely merits further exploration.
The provenance half of this is already being done elsewhere – Harvard's Public Data Project has copied hundreds of thousands of datasets from Data.gov and digitally signed them, using public-key encryption, so that anyone can verify a copy is unchanged since publication – no matter who they got it from. What I'm suggesting is to carry that same idea onto ATProto, so the signed claims are replicated and discoverable too. They write about their thinking around this in Replication of Government Datasets and the Principles of Provenance. Since drafting this I've also learned how much of the content-addressing piece already exists in and around ATProto – projects like DASL and the IPFS Foundation's Matadisco (which uses ATProto for open archive discovery, and is already being tested with GLAM and broadcast collections) are building exactly this, which is great!
Another interesting aspect of ATProto is that it's a great protocol for discovery and social sharing. At TheirStory we found that a theme that came up time and time again with archivists was that they were sitting on huge amounts of valuable content, but nobody was viewing or consuming it. Consequently we spent a lot of our time working on publishing systems and ways to curate and remix stories into a form that would drive engagement.
We already see glimpses of ATProto's social discovery potential with Blaine's ionosphere work. It's so much more than machine-generated transcripts – there are indexes of all significant terms within the talks – concepts named, entities extracted and cross-linked. There are even Bluesky posts about each talk time-aligned to the moment they reference. The discovery side is already being built.
This opens up an exciting opportunity – certainly an area I'd love to experiment in – the social sharing of archival content. The idea would be to set up a network that fosters the clipping and remixing of archival content into new, engaging forms that could be shared. I have been thinking about how Hyperaudio could facilitate this in a way that would guard against the spreading of disinformation. Even if content is authentic and verifiable it can still be used out of context. A key concept with Hyperaudio is that a remix or even a clip is referential – that is to say that it's effectively just a couple of pointers to the start time and the end time of the original content. This not only makes it easy to establish the context, but also eliminates wasteful duplication of media in various forms. It's non-destructive, which is exactly what we need, clips can be expanded and remixes can be remixed indefinitely.
I've spent far too much time working on transcript-based remixers, but I think there might be a couple left in me. Already transcript-based editing can be fairly intuitive – just drag and drop the text related to the media you want to clip or mix. I've even tried it out on primary school kids and so I'm fairly confident that it's a straightforward way of putting media together.
 The Hyperaudio Pad – An early remixer from 2013
The Hyperaudio Pad – An early remixer from 2013
I'm imagining a new social media network that could work both on a local and global level. Much of the archival content that exists is local such as "Through A Rainbow Lens" – A reflection on Lynn's LGBTQ+ History, The Black Reproductive Justice Archive or Indigenous communities such as The Kahnawà:ke Beadwork Oral History Project. But since transcripts lend themselves to being translated these stories could be disseminated globally.
What if we created a network where archival content can be curated, spread and used as a springboard to exploring the wealth of stories that make up our collective history? Something that could even be used in schools as a platform for both the production and consumption of audiovisual essays. A new bottom-up approach to oral history.
I'd love to hear from archivists who are interested in this approach and technologists that have any thoughts or are perhaps working in similar areas.
With thanks to Blaine Cook, Boris Mann and Ted Han for their feedback.
Find me on Bluesky @maboa.bsky.social or email me at mark@hyperaud.io.
Related reading
From around the web:
- On Guerrilla Archives in the Disinformation Age
- Replication of Government Datasets and the Principles of Provenance
- How the Catalan government uses IPFS to sidestep Spain's legal block
- Evidence of Internet Censorship during Catalonia's Independence Referendum (OONI)
- No Justification for Spanish Internet Censorship During Catalonian Referendum (EFF)
- No justification for internet censorship during Catalan referendum (EDRi)
- Repression and digital resistance in the #CATALANREFERENDUM (openDemocracy)
- DASL – content-addressing primitives for the web
- Matadisco: Can We Bootstrap Public Data Discovery with ATProto? (IPFS Foundation)
It turns out I've been thinking about these ideas – decentralisation, remixing, context, accessibility, oral history – for a while now. A few posts from this blog:
- Decentralise Now
- Decentralise Everything
- Rethinking Remixing
- Hyperaudio - Ethical Considerations of Building a Platform
- Fighting Disinformation with Media Literacy
- Hyperaudio for Schools
- Hyperaudio for Conferences and Grant for the Web
- The Way We Speak
- Media Accessibility
And some older posts: